


Large Language Model "Trust" - Part 1 - Defining "Trust"
Large Language Model "Trust" - Part 1 - Defining "Trust"
Fool Me Once, Shame on You; Fool Me Twice, Shame on Me

One of the many challenges I see with increased usage of Large Language Models (LLM) such as Open AI ChatGPT, Google Bard, Meta Llama and Amazon Bedrock is how users of those systems will establish “trust” with the generated results. As you will see - “Trust” is a rather involved topic - which is going to take the next several blog entries to effectively cover.
Does ChatGPT think it is trustworthy?
So we have a starting point for today’s blog - I asked ChatGPT the following 2 questions (which are pretty similar). The responses are interesting:
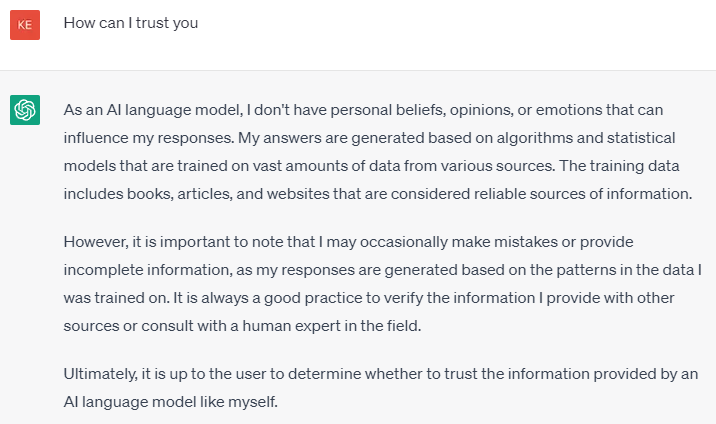
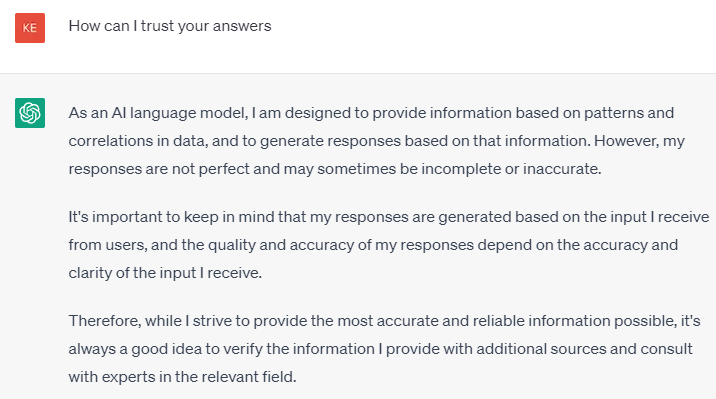
There is LOTS to take away from these responses:
It admits its answers are based on algorithms and statistics
It admits it can occasionally make mistakes
And that it is ultimately up to the user whether or not to verify/trust the results !!
And by its own admission - ChatGPT isn’t Sentient !
As you will see - there is a LOT more about “Trust” we need to consider
The Trust Challenge - TRUST vs “Personal Bias” / Reasonability + Response History + Convenience + Speed + Effort
This section represents something I refer to my friends as my “brain droppings”. I use the term “brain droppings” to describe the start of an idea that isn’t completely fleshed out - but gives enough of the idea to have a conversation.
Just the section title indicates there isn’t a single attribute that goes into establishing “Trust”. For example, think about the human relationships you have established - what were the interactions that allowed any type of trust (or distrust) to be established? And how long (or how many interactions) did it take?
I can tell you - establishing “trust” dynamics of chatbots will be MUCH different:
Will interact with chatbots MUCH more frequently than humans
Each LLM model (ChatGPT, Bard, LLaMA, etc) will in essence be like interacting with a different persona - you will need time to establish trust for each.
For the situation at hand - Does the answer need to be Right vs Accurate vs “Close Enough” (How close to a “Human” do they need to be? )
In which situations will you do the work to verify a chatbot “answer”
How do you make sure you don’t let your guard down (assume you are working on a time sensitive project with 3 different chatbots - and you forget one of the chatbots isn’t as good on a certain topic).
Yes - there is a LOT more to talk about !!
Upcoming “Large Language Trust” Topics
So that should give you some insight as to the complexity of the space - and why I will be focusing on “trust” for the next several blogs. And while none of the following blogs are written yet - this is the working PLAN - yes I do get to change my mind ;) - for how I will tackle this topic ..
Visualizing Trust (Yes I have another diagram !!!!)
Data vs Information vs Knowledge vs Wisdom
Right / Accurate / Good Enough
The Role of Explainable AI
Situational Trust - Applying what we have learned